Executing Workflows
How stored workflows become executable: the GraphBuilder, three step types, and progressive hardening.
AIM is the reasoning and action subsystem of Squad’s cognitive architecture. It sits between the user and the knowledge graph: receiving queries, deciding how to answer them, executing multi-step plans, recovering when things go wrong, and learning from every interaction. AIM is what makes Squad an agent, not just a search engine.
AIM’s design draws from several convergent threads in computational neuroscience and cognitive science. These inform the system’s core architecture, learning dynamics, and decision-making approach.
AIM is grounded in Karl Friston’s Free Energy Principle: the theory that intelligent systems survive by minimising surprise, the gap between what they expect and what they observe. Rather than passively waiting for queries, AIM operates as an active inference agent: it maintains a generative model of its environment (the knowledge graph and memory systems), makes predictions about what information is relevant, and acts to resolve uncertainty.
In practice, this means AIM doesn’t just retrieve and respond. It actively selects actions (which tools to call, which retrieval strategies to use, which clarifying questions to ask) that will maximally reduce its uncertainty about the user’s intent and the correct answer. When the system encounters something unexpected (a failed tool call, an ambiguous query, a knowledge gap), it treats this as prediction error and adapts its approach accordingly: replanning, exploring alternative strategies, or flagging the gap for human input.
The probabilistic reasoning that underpins AIM follows the Bayesian brain hypothesis: the idea that cognition is fundamentally about maintaining and updating probabilistic beliefs in light of evidence. AIM maintains confidence distributions over query interpretations, retrieval results, and execution outcomes. Each step in a reasoning pipeline updates these beliefs:
This Bayesian framing is what allows AIM to make principled decisions about when to trust a fast template match (high prior confidence) versus when to engage full deliberative reasoning (high uncertainty). It’s also why the system improves with use: every interaction updates the priors.
Closely related to active inference, predictive processing (Andy Clark, Jakob Hohwy) holds that the brain is fundamentally a prediction machine: it continuously generates top-down predictions about incoming sensory data and only propagates the prediction errors that its model cannot explain. AIM implements this through its Belief Updater: a dedicated component that sits at the front of every reasoning cycle.
When a message arrives, the Belief Updater doesn’t just parse the text. It converts the raw conversation into structured belief channels: the user’s intent, their implicit assumptions, their level of expertise, and the current state of the task. It also performs perspective-taking, maintaining a model of the user’s beliefs about the system and vice versa. These structured beliefs propagate downstream to every other component, meaning the classifier, planner, and reviewer all operate on a shared, enriched representation of the interaction rather than raw text.
This is what allows AIM to detect when a user’s question implies a misunderstanding, when additional context would change the optimal approach, or when the conversation has shifted intent mid-session. The Belief Updater is the mechanism through which AIM’s generative model stays aligned with reality.
Marvin Minsky’s Society of Mind thesis (that intelligence emerges from the interaction of many simple, specialised agents rather than a single monolithic reasoner) directly shapes AIM’s multi-agent architecture. Rather than routing every task through a single LLM, AIM decomposes problems across specialised components:
Each of these components operates semi-independently with its own specialised logic, but they coordinate through a shared state (the active working memory) that gives them a unified view of the current task. This decomposition means each component can be independently improved, constrained, and audited.
Daniel Kahneman’s distinction between System 1 (fast, automatic, pattern-matching) and System 2 (slow, deliberate, analytical) thinking is the organising principle behind AIM’s execution model. Novel queries engage the full deliberative pipeline. Familiar patterns execute via compiled workflows. The critical insight is that System 2 is temporary: over time, proven patterns can be governed and formalised into safer, cheaper execution modes.
Valerie Reyna’s Fuzzy-Trace Theory informs how SOMA’s memory systems store information at multiple levels of specificity. Verbatim traces (exact records of what happened) and gist traces (the essential meaning) are maintained in parallel. This dual-trace approach is reflected in the three-layer storage model: Layer 0 episodes capture the verbatim record, while Layer 2 entities represent the distilled gist, the generalised knowledge that persists after the specific details fade.
AIM is built on dual-process thinking: dynamically selecting the cheapest execution mode that can handle the current task:
The key insight is that System 2 processing is temporary. As patterns stabilise through repeated use and human approval, they graduate into System 1: compiled workflows that execute automatically. Every workflow starts in System 2 and, with enough evidence and oversight, can be hardened into System 1.
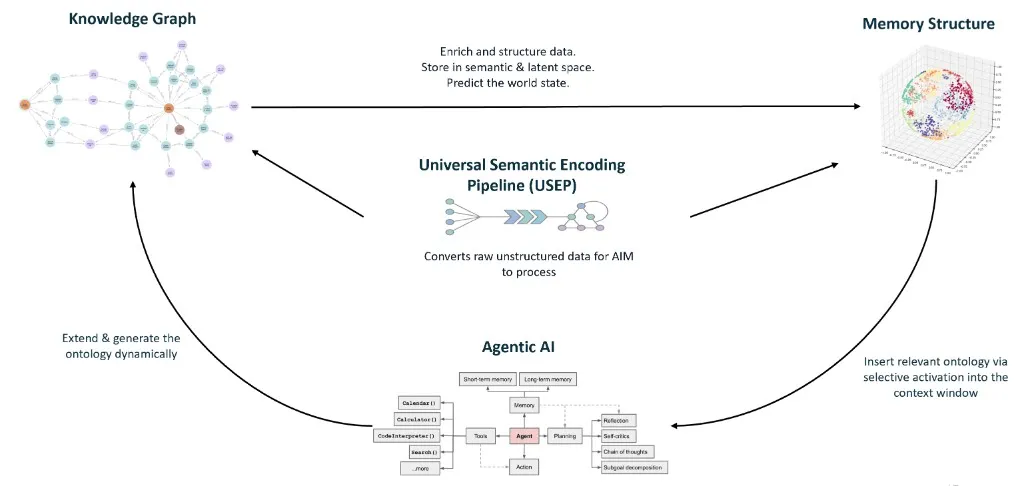
Squad’s architecture is inspired by Active Inference: the theory that intelligent systems continuously act to reduce uncertainty about their environment. Data flows in through perception, integrates into memory, drives decisions through reasoning, and environment feedback loops back to refine the system’s beliefs.
The loop runs continuously: Ingest → Encode → Store → Retrieve → Reason → Execute → Observe → Attune → Ingest …
The diagram below shows AIM’s internal structure: the core pipeline, recovery systems, and memory integration. When System 2 engages for a novel query, all of these components participate in the full deliberative loop.
The Core Pipeline runs from Belief Updater through Classification, Planning (with sub-planners exchanging beliefs in peer rounds), Execution, and Review. The Recovery & Disambiguation subsystem activates when the standard path gets stuck: the Explorer diagnoses failures, the Disambiguator clarifies user intent, and Tool Creation fills capability gaps. Memory & State provides the working context and long-term persistence that connects everything: working memory holds the active session state and structured belief channels, while long-term memory stores reasoning traces, learned beliefs, and user models across sessions.
The architecture reads from and writes to the knowledge graph at every stage: retrieval pulls context from the semantic layer and procedural memory, while execution writes traces back to episodic memory. These traces support ongoing consolidation and improvement over time.
Every user message flows through a structured pipeline that classifies, plans, executes, and reviews before responding. This is the System 2 path in detail.
Before any classification or planning, the Belief Updater converts the incoming message into structured beliefs. It extracts the user’s intent, assesses their implicit assumptions and expertise level, and performs perspective-taking to maintain a model of the user’s expectations. These structured beliefs, not the raw text, are what flow into every downstream component, ensuring the entire pipeline operates on a rich, contextualised representation of the interaction.
With structured beliefs in hand, AIM classifies the query’s intent: is it a factual question, a recommendation request, a procedural task, or something ambiguous? It also assesses risk level. This classification determines the route: ambiguous queries go to disambiguation, clear queries proceed to retrieval and planning.
AIM searches for similar previously-answered queries using vector similarity. A high-confidence match means the system can reuse a proven approach directly: skipping planning entirely. This is how the system gets faster with use: familiar questions are answered via proven templates, not re-planned from scratch each time.
When a query is ambiguous, AIM asks a targeted clarifying question designed to maximise information gain: picking the question that best narrows down what the user wants. The system allows multiple rounds of clarification before proceeding with a best-effort response.
For novel queries without a proven template, AIM decomposes the task into a sequence of steps: each specifying which tool to call, what arguments to use, and what the step should achieve. The planner draws on the tool registry and any partially-matching workflow templates to construct the most effective approach.
Steps are executed one at a time by the executor, with the reviewer validating each result against quality and security criteria. If issues are found, the planner replans with failure context. This plan-execute-review loop can iterate multiple times, allowing recovery from partial failures.
For details on how plans become executable workflows, including the three step types (deterministic, masked LLM, and agent loop), see Executing Workflows.
When the standard approach gets stuck after repeated attempts, AIM activates the Explorer: a structured recovery system that diagnoses the failure and tries progressively broader strategies:
When the Explorer identifies a genuine capability gap (a task that no existing tool can handle), AIM can generate new tools to fill it. Generated tools go through human-in-the-loop approval before entering the tool registry, where they become available for all future workflows. This is how Squad’s capabilities grow organically from real usage.
Executing Workflows
How stored workflows become executable: the GraphBuilder, three step types, and progressive hardening.
Accuracy & Disambiguation
How the system avoids wrong answers: disambiguation, confidence routing, and human-gated templates.
Workflows
How proven workflows are stored as Workflow → Step → Tool graphs in procedural memory.
Guardrails & Safety
Security controls throughout the pipeline: risk-aware routing, review, and human-in-the-loop approval.